At a glance
- MOOCs
- Collections (SCP-007)
- scalajs-bundler
- Bloop
- Pipelined compilation
- Zinc
- Scalac
- Dotty
- Bugfixes
- Scalafix v0.8.0. released
- Scalameta
- ScalaDB
- Other activities: conferences, talks, sprees, SIP, ScalaDays 2019
MOOCs
In collaboration with Roland Kuhn and Konrad Malawski we worked on our “Programming Reactive Systems” course. We completed the implementation of the assignment about Akka-Streams and wrote the instructions for it; reviewed the assignment on Akka-typed (implemented by Roland Kuhn) and adapted it to our grading infrastructure. Also reviewed the contents of the lectures for Akka-typed.
Upgraded our grading infrastructure and our assignments to sbt 1.x.
Collections (SCP-007)
-
Worked on migrating existing libraries to Scala 2.13.0-M4, and trying to make that process easier by automating and documenting it.
-
migrated ParIterable, ParSeq and ParVector from the parallel collections and detailed the path to follow to migrate the remaining collection types. #42
-
collaborated with @MasseGuillaume on scala-collection-compat and reviewed several collections related PRs on the scala repository to reduce the number of incompatibilities from Scala 2.12 to 2.13.
-
reviewed the migration of scala-stm.
-
wrote a guide on programming generically with collections #1088, along with the implementation of a framework for doing so #6674.
-
wrote a guide describing the architecture of the new collections and how to implement custom collection types #1078.
-
wrote a blog article explaining the differences between the old and the new collections from the point of view of end-users #909.
-
refactored the implementation of builder-based transformation operations #6776.
scalajs-bundler
Reviewed and merged PRs. A new version (0.13.0) has been released by Carlos Quiros.
Bloop
- Bloop v1.0.0 was released. Release notes.
- Bloop v1.1.0 will contain performance improvements and build pipelining.
- Latest master implements a gradle-bloop plugin. Gradle users can now benefit from faster compilation. Check this tweet.
Build pipelining
Build pipelining is a technique proposed by Rory Graves at Scalasphere 2017 to speed up compilation of build graphs. Builds usually compile modules in their topological order, allowing for parallel compilation at the build level. In order to compile a given module, all its project dependencies need to have been compiled before. Build pipelining allows the compiler to start the compilation of a given project right after all its project dependencies have been typechecked.
This idea, then presented as pipelined compilation, has evolved into build pipelining. We have worked out all the technical details of the implementation in Bloop, which we intend to make reusable for all build tools.
Build pipelining has been merged in Bloop master. The current prototype, which is still under performance work, has required changes to Zinc and, most notably, Bloop which had to change the way parallel compilation works in the presence of pipelining.
Despite a lot of progress surmounting most of the technical challenges to get a production-ready implementation, the performance implications are not completely clear at this moment and there is a lot of ongoing experiments in tweaking performance and semantics.
Zinc
Zinc is becoming a more critical piece of the compilation pipeline as the main compiler becomes faster and faster. During this term, we have focused on performance and correctness fixes, but also devoted a significant part of my time to rethink the way we do incremental compilation. Regarding this last point, we have some thoughts and work-in-progress improvements that will be made public in the next term, together with benchmark results.
- Detect changes in private trait definitions. We add a new API change to detect changes in the private API of a trait. Private definitions in trait require the recompilation of all sub classes. After this change, this behaviour is kept and link exceptions at runtime avoided.
- Allow running the incremental compiler algorithm right after pickler. This pull request moves the recollection of critical information from the analysis phase (which runs after genbcode) to the API phase. Check the pull request for a detailed explanation of what this entails and how it can improve performance of the incremental compiler, as well as several diagrams.
- Fix bug detecting default arguments changes in separate compilation. The error, originally reported by @OlegYch, was caused to a compiler bug in the class file reader that does not set the associatedFile field in any symbol that defines default arguments (class or method).
- Infrastructure work to speed up scripted test execution. Scripted tests were quite slow to run because required the constant publication of jars, that cost is gone by using build-info.
- Regular review work and unblocking of PRs in the queue (more than 10 PRs merged from several contributors, some of them improving core APIs).
- Document thoroughly the invalidation algorithm in Zinc. This pull request tries to fix Zinc’s reputation of poor documentation to make future improvements in this area easier to read and bug fixing possible by external contributors.
- Add profiler to the invalidation algorithm. Instrumenting the invalidation algorithm allows two important future use cases:
- Persistence of the invalidation algorithm choices for off-line analysis.
- This analysis can be added to tools like Bloop to help organizations learn more about what are the source files that are more often recompiled and why, for example.
- Semi-automatic bug reporting to simplify reporting incremental compiler bugs.
- Tools like Bloop can detect when a link error happens when running an application and suggest to the user that the error may be related to the incremental compiler, and propose a way to report the issue by attaching the persisted incremental runs’ data.
- This is desirable because reporting incremental compilation bugs demands too much effort:
- Affected users must have the time to find a reproduction at a moment where they are working on their software to add a feature or fix a bug;
- Reproducing bugs requires expertise to second-guess the incremental compiler behaviour and some familiarity with how the compiler works, which most of the affected users lack.
Scalac
- Discussed with Jason Zaugg about build tools and compiler APIs. Our discussions started in https://github.com/scala/scala-dev/issues/548 and https://github.com/retronym/scala/pull/27 in the context of implementing classpath caching in a safe way and enable it by default.
- In a following chat, we discussed the specifics of his prototype and decided to expose a programmatic API to: open and closed JARs and the management of pickle information.
- Manage how build tools and compilers interact with regards to jar creation/load.
- Find general-purpose ways to propagate pickle information and manage it by the build tool.
Dotty
Features
Display documentation directly in IDE
In the previous quarter, we’ve spent time improving TASTY so that it can hold documentation. Thanks to this improvement, it has become possible to display the documentation directly in the IDE by leveraging the information that we already have at hand in TASTY.
We’ve been working on Dotty IDE so that when hovering over a symbol, the IDE extracts the documentation from TASTY and displays it to the user.
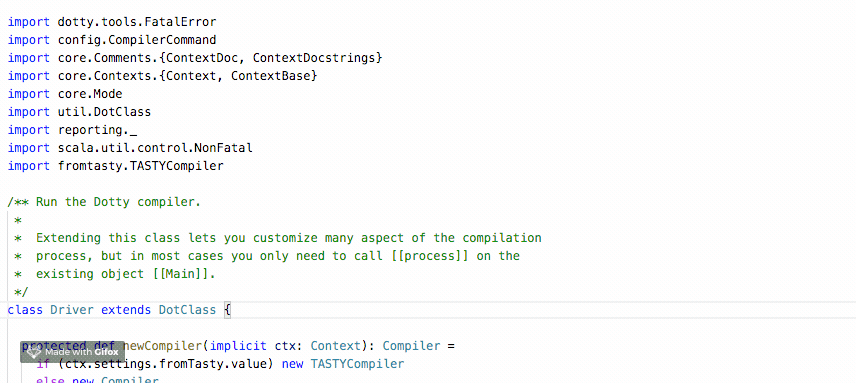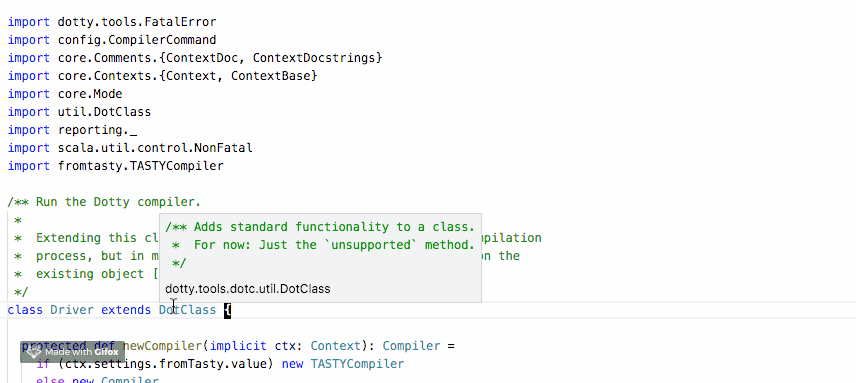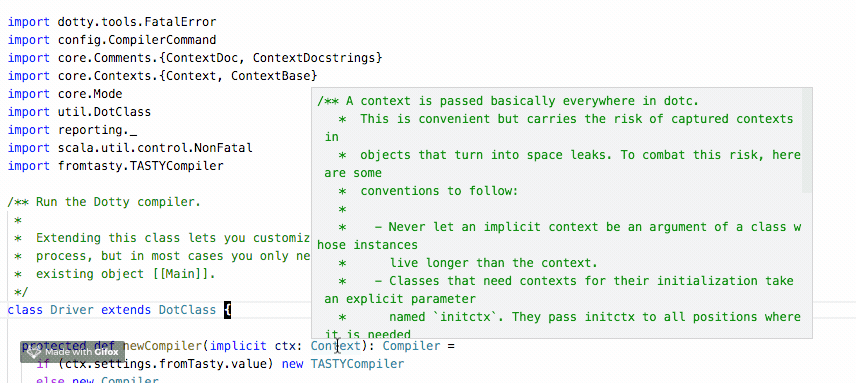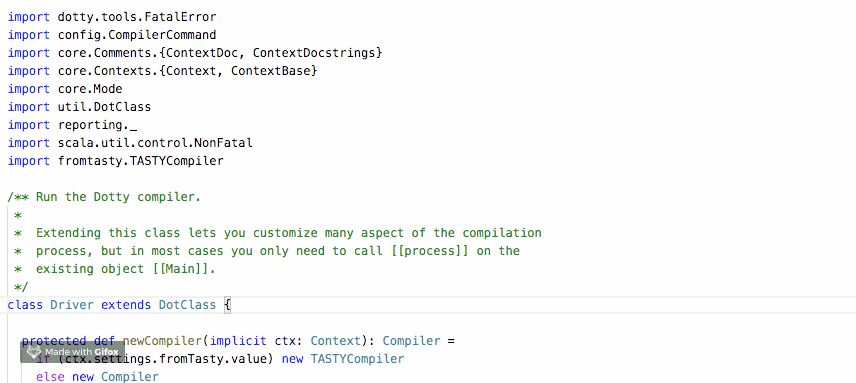
This work: https://github.com/lampepfl/dotty/pull/4648
Display documentation in the REPL
Again, by using the previous improvement to TASTY, we can now get the documentation directly in the REPL.
The REPL now supports a new command, :doc, which will display the documentation relative to the symbol that it receives in input:
scala> /** A class / class A
scala> /* An object / object O { /* A def / def foo = 0 }
scala> :doc new A
/* A class /
scala> :doc O
/* An object /
scala> :doc O.foo
/* A def */
This work: https://github.com/lampepfl/dotty/pull/4669
Support -from-tasty in Dottydoc
In dotty, we use the -from-tasty to instruct the compiler that it should, instead of reading source file, work using the trees that can be unpickled from TASTY.
Given that documentation comments are now included in TASTY, we worked on adding support for the -from-tasty flag in Dottydoc.
Being able to generate the documentation from TASTY has several advantages over extracting them from the source file:
- Generating the documentation can be made incremental, because the TASTY files can be created incrementally.
- It is much faster, since we do not need to typecheck the code again.
We worked on making Dottydoc support -from-tasty so that the documentation can be generated using only the TASTY files.
This work: https://github.com/lampepfl/dotty/pull/4789
Support Dottydoc in sbt
Prior to this work, Dottydoc couldn’t be used directly from sbt and required users to invoke it as a standalone tool from the command line.
Integrating Dottydoc with sbt was hard because sbt expected that the documentation tool used to live in the same JAR as the compiler, which is no longer true.
Dottydoc can now be directly be invoked from within sbt using the doc task.
This work: https://github.com/lampepfl/dotty/pull/4952
Support completion for renamed imports
Dotty IDE provides the user with smart code completion which include the symbols that have been imported. However, Dotty IDE wasn’t smart enough to display the symbols after the renamings that can happen in import clauses:
import org.myorg.{MySymbol => MyRenamedSymbol}
class Foo extends My<tab> // Dotty IDE used to suggest MySymbol
This was improved by teaching Dotty IDE to remember how symbols were renamed, so that it can display the correct completion options.
This work: https://github.com/lampepfl/dotty/pull/4977
Support go-to-definition on named arguments
In the following function call:
def foo(myArg: Int) = myArg + 1
foo(myArg = 321)
Using go-to-definition on myArg, the user would expect to be taken to the declaration of myArg inside def foo. Dotty IDE was not handling this situation correctly, and no definition would be found.
We taught Dotty IDE where to take the user by finding the function that is being called, and then finding the matching parameter.
This work: https://github.com/lampepfl/dotty/pull/5057
Support multi-project setups in Dotty IDE
This is the first part of a series of pull requests that aim at supporting multi-projects setups in Dotty IDE.
Currently, certain features of Dotty IDE, such as find all references or rename, do not work well when a project is split across several different modules. Other features, such as go to definition work seamlessly.
This first pull request improves the testing framework that we use for Dotty IDE, so that it is easy to describe multi project setups and tests can be performed on such configurations.
We have also prototyped support for find all references and renaming in multi-project setups, but haven’t submitted a pull request yet (I’m waiting for this one to be reviewed, first).
The hard part of multi-project support is teaching Dotty IDE how to compare symbols that live in different instances of the compiler. My experimentations show that this can be done by re-creating instances of a symbol S in compiler C1 by walking its owner chain and selecting the symbols with the same name in compiler C2.
This work: https://github.com/lampepfl/dotty/pull/5058
Worksheet mode in Dotty IDE
For Scala 2, both IntelliJ Idea and Scala IDE offered a worksheet mode, which is similar to the console task in sbt: it opens a REPL with a project and its dependencies on the classpath. This is very useful to be able to quickly experiment.
No such tool was available for Scala 3, so We started working on a worksheet mode for Dotty IDE. These worksheets offer an experience very similar to the worksheet mode in IntelliJ Idea or Scala IDE.

This work: https://github.com/lampepfl/dotty/pull/5102
Bugfixes
Cook comments on empty classes
Dottydoc is the documentation tool that we use to generate documentation from the comments embedded in the source code. Unfortunately, it suffered from a bug where the documentation comments that were set on classes that had no members would not be cooked.
We fixed this bug while working on Dottydoc.
This work: https://github.com/lampepfl/dotty/pull/4751
Show implicit modifier in implicit function types in Dottydoc
When presenting types, Dottydoc was not showing the implicit modifier in implicit function types, because it was using logic to display the types that was introduced before the implicit function types.
We fixed this bug by removing the old, incomplete logic and reusing the code used in other parts of the compiler.
This work: https://github.com/lampepfl/dotty/pull/4954
Exclude constructors when finding references
Finding references is used in many places in Dotty IDE, as a standalone feature and to support other features, such as renaming for instance.
When finding references, we used to wrongly include the synthetic constructor <init>, which lead to unexpected behavior. For instance, trying to find all references to a class name would return the class, but also the synthetic position of this constructor. When renaming, we would try to rename this constructor, leading to broken code.
We fixed this problem by factoring out the logic that finds references to a symbol and always excluding this synthetic constructor: It should never be seen by the user anyway.
Relevant ticket: https://github.com/lampepfl/dotty/issues/4995 This work: https://github.com/lampepfl/dotty/pull/5047/files
Respect -color:never in REPL output
Dotty has a -color option that can be used to tell when its output should be colored. This is useful, for example, when using a terminal that doesn’t support ANSI escapes or redirecting output to a file.
The REPL was ignoring this option, and always displayed colors in its output.
This work: https://github.com/lampepfl/dotty/pull/5098
Scalafix v0.8.0. Released
- v0.8.0-RC1 release notes: https://github.com/scalacenter/scalafix/releases/tag/v0.8.0-RC1
-
New documentation: The new website contains improved docs for custom rule authors and sbt installation instructions. New content on the website includes:
- Rule author tutorial
-
API reference overview in addition to dedicated pages for key components:
- Patch: to rewrite sources
- SymbolMatcher: to match interesting tree nodes
- SymbolInformation: to query metadata about symbols
- SemanticType: to inspect types of variables
- SemanticTree: to query inferred type parameters and implicits
- Improved sbt installation instructions
- Improved performance: users have reported speedups from 65 minutes to 2 minutes when running custom Scalafix rules on a large codebase.
- Improved sbt plugin
- no more binary conflicts with sbt classpath.
- custom rules published to Maven Central (such as scala-collection-compat) are now easy to run from the sbt plugin.
- build mis-configuration such as missing compiler options are reported by Scalafix before compilation starts, helping users discover problems early on.
- syntactic rules run without triggering compilation, significantly speeding up common use-cases.
- New zero-dependency Java module scalafix-interfaces with public APIs designed for build tools, see Javadoc. This API is used by the sbt plugin.
Scalameta
In close collaboration with Eugene Burmako and his team at Twitter we released Scalameta v4.0.0.
- v4.0.0 release notes
-
New documentation: The new website aggregates Scalameta documentation in one place.
- New trees guide: learn how to parse, traverse and transform syntax trees.
- SemanticDB guide: getting started with metac, metacp and metap.
- SemanticDB specification: detailed reference to learn about SemanticDB in-depth.
ScalaPB
We contributed a new feature called "sealed oneof" to generate idiomatic Scala sealed traits from a subset of a Protobuf oneof messages. The sealed oneof encoding greatly improves the ergonomics of using types, synthetics, signatures and constants in the new SemanticDB v4.
Pull request: #458.
Other activities: sprees, talks, conferences, SIP meetings
Scala Days New York, 19-21 June 2018
Scala spree
In collaboration with TAPAD and LightBend who hosted and sponsored the venue, the Scala Center team organized a Scala spree on 19th of June. After the success we had in Berlin, we were able to reach out and organise the Scala spree in a short period of time with a great outcome. There were about 50 participants that had an opportunity to work on the Scala compiler, Dotty compiler, sbt, Scalafix, Bloop and InteliJ . By the end of the event, 8 pull requests were merged into sbt, 10 people completed an intensive Scalafix workshop, 2 long-standing issues were closed in Bloop and more. Scala Days takeaway blog mentioning the spree Spree photo
Talks
Julien Richard-Foy and Stefan Zeiger presented “Migrating to Scala 2.13” Abstract
Martin Duhem and Jorge Vicente Cantero presented "Meet Bloop" Slides
Scala Italy, Florence, 14th - 15th Sept
Ólafur Páll Geirsson hosted a 90 minute workshop at Scala Italy on using the latest Scalafix semantic API to refactor and lint Scala code, link.
Advisory Board Meeting June 2019
A yearly in-person meeting took place at Morgan Stanley offices, NY on the 19th June 2018.
SIP Meetings: June, August, September 2018 + extensive SIP in November
In May (minutes) SIP Committee decided to review the future changes considering upcoming Scala 3. They met in June, August and September discussing the first two batches, and the community discussions about both batch 1, batch 2.
The SIP committee agreed that given the scope it would be good to meet in person for a couple of days to get ahead of the workload. Extensive SIP meetings, with 8 out of 9 members will take place on the 1st, 2nd and 3rd of November 2018 at EPFL, Switzerland. We will include the Community, but are still figuring out the program and timings - more info closer to the date.
To read/watch more about the SIP:
September 2018 please go to: minutes or watch the meeting on Scala Center’s YouTube channel.
August 2018 please go to: minutes or watch the meeting on Scala Center’s YouTube channel.
Scala spree evolution
As of Scala spree in Berlin, day of ScalaDays opening, we got more requests to help organise / coordinate the sprees around other conferences. We decided to create a “DIY manual” (in the process) based on our experience so far. This resulted in organising 2 sprees in a different setting than before:
Amsterdam, 19th July, day after the Curry on conference, sponsored and taken place at ING offices.
This was the first spree organised around a non-Scala conference, which made it a bit difficult to efficiently gather maintainers - which is why we reached to the local community and companies that have Scala library authors. On the day we had around 50 participants and 8 maintainers.
Gdansk, 8th September, day after ScalaWave conference, sponsored and took place at Scalac offices
First time we coordinated a spree without our on-site presence, got a great feedback.
We concluded that Scala Center is capable of supporting the coordination and communication between on-site partners without us necessarily being there, which allows scaling the number of sprees around the world. Also Scala Center get’s the opportunity to be more involved in local communities helping out with certain logistical steps.
We are happy that sprees are becoming a stand-alone event, especially after all great feedback we gathered from many participants (see the blogs, Spree Berlin, Spree NY).