Taking a step back to squint at the bigger picture, I guess many of us are thinking about our future in the light of things like cursor and copilot and I am wondering what all Scala-friends here think about the future relationship with the Scala language/compiler/tooling and the role of developers given the rapid evolution of automation capabilities enabled by large language models.
Here is a whiteboard sketch I made that may be food for thought, based on the hypothesis that there will be trained AI components “everywhere”, and that the compiler IO is connected to an “automatic coder”:
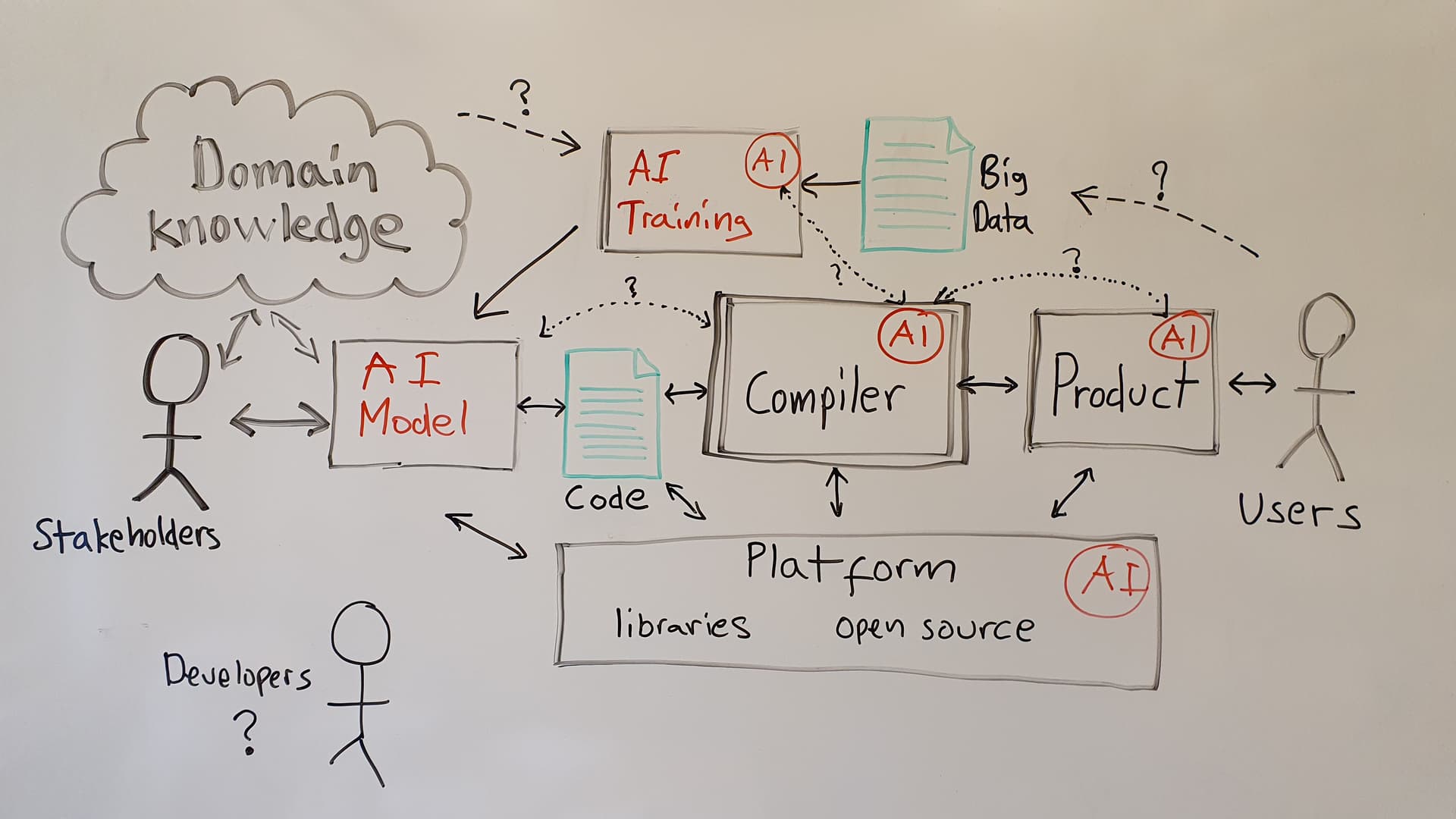
- We already have standardized error output that may help training AI on compiler IO, but what more cool things can be done from the language, compiler and tooling side to facilitate automation based on LLMs etc.?
- Are there some “low hanging fruits” in language, compiler and tooling evolution that you think would make Scala stick out in the race?
- With the current Scala and its ecosystem, are there specific things with our favorite language that you think make Scala particularly suitable for LLM-supported coding?
(This is an attempt to kick-off some forward-looking requirements elicitation in our joint endeavor of requirements engineering for our favorite language ![]() - any contributions welcome on goals, non-goals, features, qualities, opportunities, challenges, … with a long-term horizon in mind.)
- any contributions welcome on goals, non-goals, features, qualities, opportunities, challenges, … with a long-term horizon in mind.)
