Hello,
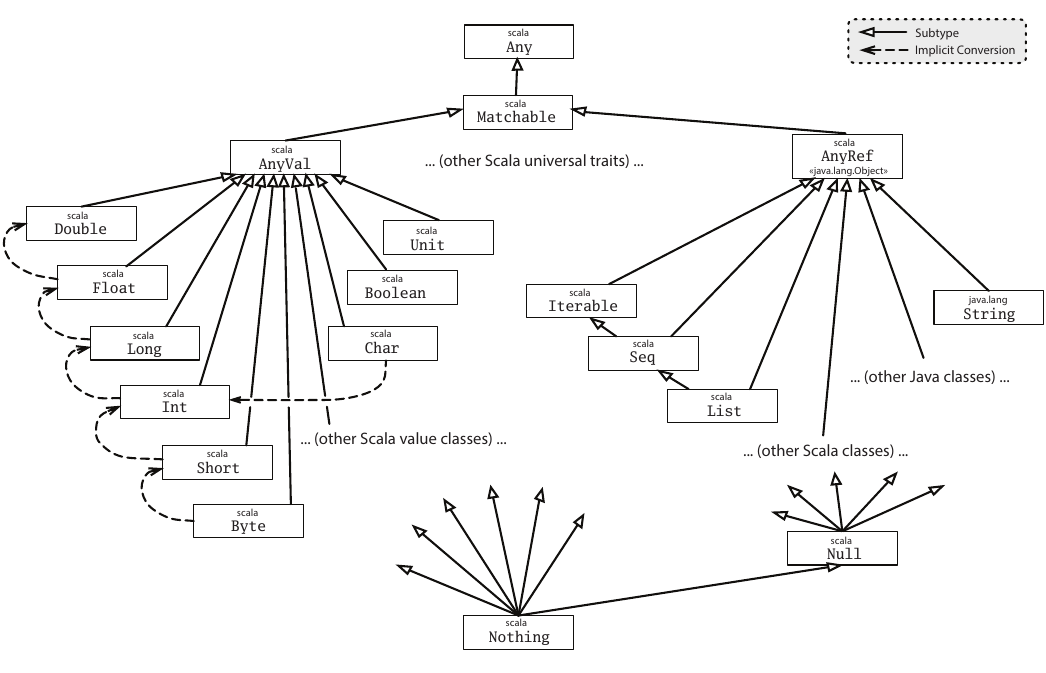
Currently, under the normal type system, Null is a magical type. It’s not really a class (despite how it’s presented in the doc. It has special rules to make it a subtype of every reference class type. This is illustrated by the following class diagram:
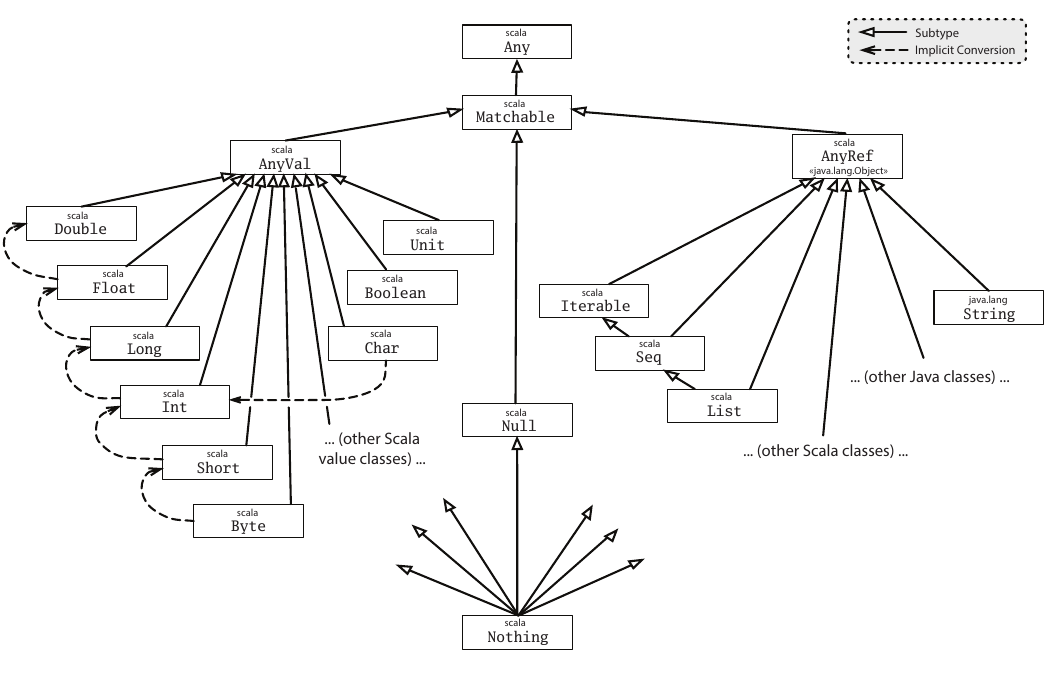
Under -Yexplicit-nulls, Null is less magical. In the core type system, it is almost a regular class (with a single instance null), which extends Matchable (and hence Any). There are no special subtyping rules in the core type system for Null anymore. (There are new type checking rules for flow typing, but that’s a different story.) This is illustrated by the following diagram:
Problem: Null is now sitting front and center in the Scala class hierarchy. It’s painfully obvious that you have to learn about it. Given it’s position, clearly it is a very important type that everyone should know about! That’s not the impression we want to give. In a world with -Yexplicit-nulls, you should be able to learn about Scala without learning what Null and null even are (until you need interop scenarios and/or expert-level performance tweaks).
Proposed solution: Move Null under AnyVal. Make it no more special than Int or Unit. The move is illustrated here:
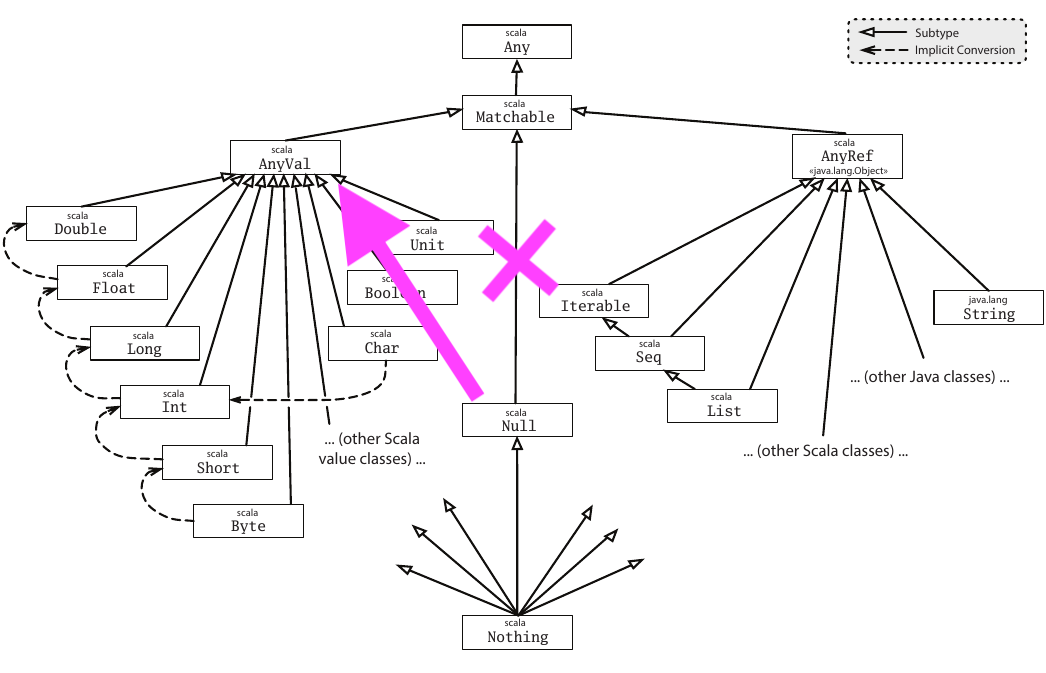
Now
Null is not front and center in the diagram that every beginner should learn. It’s possible to teach a lot of Scala without ever mentioning it.
Null has all the properties of a value class: it has == but not eq; the (only) instance can be obtained from a literal syntax (namely, the keyword null), and that instance is indistinguishable from other instances obtained that way (unlike "foo" and "foo", which could be distinct instances that are not eq). Therefore, it makes perfect sense to “hide” it under AnyVal. If you have trouble wrapping your head around this, observe that null: Null and (): Unit have a lot in common.
Historical note: at the beginning of the explicit-nulls experiment, Null was still a direct subclass of AnyRef. This was not great. It is not rare to use AnyRef as an upper bound for some T <: AnyRef. That gives you the ability to perform eq on Ts, for example. With Null under AnyRef, you could not rule out that T would in fact be nullable. That meant it wasn’t safe to manipulate a T | Null for performance-sensitive code, for example, and there was no way to define T to make it safe. With Null separate from AnyRef, that becomes safe.
Why is that not an issue with Null <: AnyVal? Because unlike AnyRef, AnyVal is useless as an upper bound. It does not give you any power that Any does not give you already. Moreover, the performance argument of manipulating a T | Null when T is not an AnyRef does not hold, since it may require boxing. In practice, it is very unlikely that there exists a meaningful T <: AnyVal anywhere.
I submitted a PR for this change here:
WDYT? Any objection?