I’m not sure what the point of this is. If S and T are sets, S may be a subset of neither T nor ~T . That’s absolutely right. Why is it any different for types?
It relates to your example given above, if we say (A | B) \ B == A, then we don’t regard types as sets and \(Type,Type):Type acts differently, in some sense in a syntactic way only.
@sjrd@Ichoran FWIW, here is a place where negation types would be useful.
The semantics of TypeTest[S, A] was recently changed from "test whether S can be downcasted to A" to "test whether a value of type S is also of type A". This means it should not only be a sound type test, but also a complete one. So the current signature for its unapply method is incorrect:
Indeed, one can easily implement TypeTest instances (for example ones that always return None) which will create match crashes down the line. Any instance defined for the old semantics may also silently become unsafe, for the same reason.
The right type for unapply should conceptually be:
In general, negation types would not be useful with anything concrete. They would mostly be useful as soon as we start abstracting over concrete types. This includes uses inside type inference engines (I’m currently writing a paper about this).
The semantics weren’t changed. They were always designed as such. But the old formulation wasn’t clear, so we made it clearer.
I agree that the type signature would be stricter if we could use a negation type. But that doesn’t make the current signature invalid. A signature is not the whole truth about a method. Its contract (documentation) is also relevant. It’s like implementing equals(that: Any): Boolean = false: sure the compiler lets you do it; no it doesn’t make it a valid implementation of that method, because you’re not respecting its contract. Or like implementing def sum(a: Int, b: Int): Int = a - b. That’s not valid either. Likewise, implementing TypeTest.unapply with something that returns None when x is in fact an instance of T is not a valid implementation.
The ability to define def without[A, B](a: A): A without B, for some “difference” operator without, and have it work for both unions and intersections, would be enormously useful. (For one, operators that eliminate some errors but not all need the ability to subtract types from a union of types.)
You can get it sort of working in some limited cases in Scala 2.x for intersections, but it is not robust.
Error handling is probably a “killer use case” for difference for unions; while heterogeneous maps are probably a “killer use case” for intersections. In errors, you want to say you can eliminate some but not all; in heterogeneous maps, you want to say you can remove specific entries. Both error handling with union types and heterogenous maps would be much more powerful and usable with such capabilities.
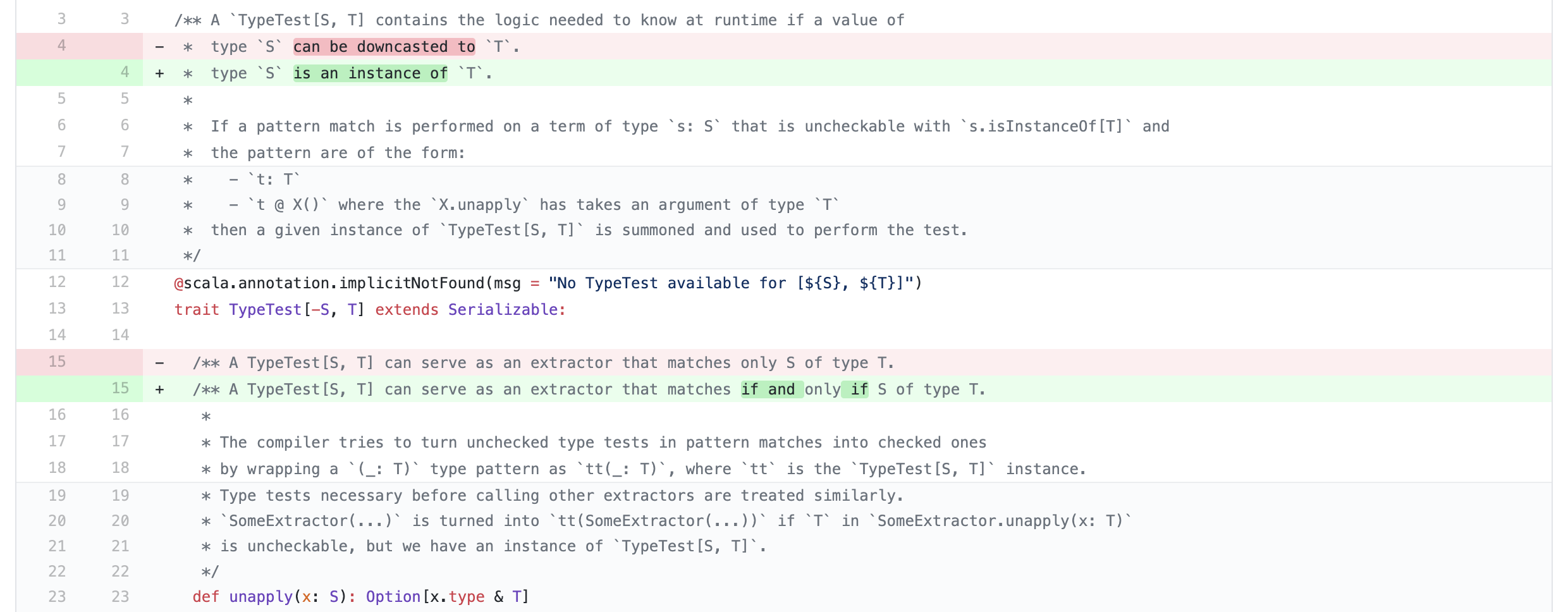
As you can see, before that, nowhere in the documentation was it implied that the type test implementation should be complete (i.e., should cover all of T). Notice how “an extractor that matches only S of type T” was changed to “an extractor that matches if and only if S [is] of type T”.
Moreover, this was not simply a documentation problem. The compiler itself did not assume that TypeTest had complete semantics. The logic for doing so was simply missing, as you can see from the full diff.
This was probably a design issue, where the bug was in the specification itself, rather than in the documentation/implementation. It turns out that the compiler developers did not specify and implement what they truly wanted to, and they have now fixed that. But this does not change the fact that the specification of TypeTest's semantics was changed, in a silently breaking way.
I designed TypeTest, together with Nicolas Stucki. You are trying to convince me that my own intentions were different than what I recall them to be.
TypeTest was always meant to be a reification of an isInstanceOf test. It was designed to replace the broken type tests based on ClassTags, known to be unsound. It was designed to be complete. It was notably motivated by the need to perform type tests for the abstract type members in the compile-time reflection API, which is a use case that absolutely requires them to be complete to be useful in any way.
The fact that the doc was not precise enough was a documentation bug. Yes, documentation bugs are bugs in their own right. But they happen, and they don’t necessarily mean that the intended spec was wrong or changed. You point out that that “only if” was changed to “if and only if” as proof of intent; but in casual speech “only if” is often used when one means “if and only if”. If you’ve never written a doc that did not correctly reflect your intended spec, cast the first stone at me.
The fact that the pattern matcher exhaustivity checker did not use the knowledge that it was complete was not a bug. It was simply because we did not implement it/thought to implement it right away. Exhaustivity checking is not perfect and has never been. For example it doesn’t know how to deal with guards or custom extractors in general. Well it didn’t know how to deal with TypeTest, same as any other custom extractors, but now it does. Adding that support does not change the meaning of TypeTest, not any more than (somehow) adding support for general custom extractors would change the meaning of custom extractors.
Please read my message again, and tell me where I am doing that.
Then it was ill-designed. More specifically, the official, documented specification for the semantics of TypeTest was ill-designed. That actually confirms my suspicion that “the developers did not specify and implement what they truly wanted to”, as I wrote in my previous message. We actually agree.
By the way, I know you took part in this, and I am aware of the original motivations.
I never said the intended spec was wrong or changed. I said the actual spec was wrong and changed. In a silently breaking way.
First, there was no “only if” in the original doc. There was: “an extractor that matches only S of type T”. Which I take as an awkward way of saying “only instances of S also of type T”. Casual speech or not, this is a spec for sound but not necessarily complete instance testing. You specifically did not write the intended “all instances of S also of type T”.
And second, I never tried to prove your own intent either way. I only made a suggestion that your intent was different than the actual specification (and implementation), and I was right, as you later confirmed.
What is this? One is not allowed to point out imperfections in Scala 3 unless one is perfect? You’re not going to get a lot of community feedback, under this policy.
Well it does actually change its meaning. A user that happens to use a TypeTest implemented against the previous spec may start getting runtime match errors from code that does not raise any compiler warning, whereas the same code would have usually raised a warning before.
Which everyone should expect, despite the lack of extra precision in the language, should mean that it’s actually complete (whether or not the compiler knows that it is–there are plenty of complete things that the compiler doesn’t know about!).
Well, that’s certainly not the only way to read what you wrote. You contrasted the documentation from the specification. There’s no way that makes sense except in light of the specification being something else intended that is different than both documentation and implementation:
So, anyway, I advise a little bit more politeness and a little less inferring the intent of others.
Regardless of what people intended at the time, any changes to behavior have to be considered in light of the old code being in the wild. But the new behavior seems strictly more sensible. So I don’t see that there’s much reason to argue about the process that led us to this point unless it’s part of a pattern that we need to prevent from happening repeatedly–we can just address the situation as it stands now.
@Ichoran tanks for the feedback. I realize what I wrote could be construed in ways I did not really… intend.
I completely disagree with that. Words have precise meaning, especially in the context of CS and SE. One would expect these precise meanings to be the ones that are intended when documenting the contracts that a piece of software is supposed to obey. When the types say it all, it’s okay for the documentation to not be as precise, but it’s specifically not the case here (which was the original point of this whole conversation).
It does not really matter, though. For what it’s worth, I totally agree that the complete-test semantics is the right one, and I even agree that it was the right thing to do to change the documentation and extend the implementation now. But you have to call a breaking change what it is, instead of inventing new meanings for old sentences.
You’re right that what I wrote was confusing. I did not mean to say Sébastien and Nicolas intended for TypeTest to not be complete. I meant to say that when they got down to business to document and implement TypeTest, they followed the wrong informal specification, forgetting about completeness. This is obvious from the old doc, which was only stating half of the contract, making it broken or at best misleading (there’s a reason it was rephrased in the first place). I realize this is already too much “inferring” on my part, though, and I may be wrong about it. Apologies for entertaining this nitpicking battle.
Are you sure it is nitpicking? Won’t a commitment to soundness tend to require an OCD level of communication precision and accuracy because it’s literally the nature of soundness itself?
IOW, uncomfortable communication redundancy now is preferable to unintended soundness defects later, right?
It’s nitpicking to argue about whether something is genuinely a specification change or whether it’s “just” clarifying intent and fixing a bug.
Precision in language good idea when it could possibly be ambiguous otherwise, and/or a better presentation can lead one to think more carefully about how what constitutes correct behavior.
You can kind of do something like this, at least for intersections, in certain cases of what you need to have inferred (I think I’ve mentioned this in a few channels, but it doesn’t look like I’ve mentioned it here yet):
This works in Scala 2.11+, AFAIK.
// this is only to verify the expected type.
import scala.reflect.runtime.universe.{TypeTag, typeTag}
trait SpookyFunction[-In, +Out] {
def andThen[NextIn <: In, NextOut](
next: SpookyFunction[Out with NextIn, NextOut]
): SpookyFunction[NextIn, Out with NextOut] =
new SpookyFunction[NextIn, Out with NextOut] {}
}
trait A; trait B; trait C; trait D; trait E
object Foo extends SpookyFunction[A with B, C]
object Bar extends SpookyFunction[C with D, E]
object Example extends App {
// to see what's inferred
def showType[T : TypeTag](t: T): Unit = println(typeTag[T])
// Expected: TypeTag[SpookyFunction[A with B with D,C with E]]
// Why? Because even though Bar requires C, it is provided by Foo and so it can be eliminated.
showType(Foo andThen Bar)
}
It’s very sensitive to the order in which you specify the with types, at least in Scala 2. E.g. in the andThen, next: SpookyFunction[NextIn with Out, NextOut] doesn’t give the desired inference, while next: SpookyFunction[Out with NextIn, NextOut] does. Haven’t had the opportunity to try this in Scala 3.
(edit: I mentioned this again only because I suspect that @jdegoes’ interest in this starts with ZLayer, and the thing I mentioned could possibly apply to that. Wasn’t trying to disrupt the conversation here)